12.11. Examples¶
12.11.1. Ingest a GeoMesa Kafka Topic into HBase¶
A common use case is to store the most recent state of an object in a GeoMesa Kafka data store to drive a live map view, and to persist every state of the object into long-term storage in HBase or Accumulo for history and analytics. This example will show how to pull data off a GeoMesa Kafka topic, and persist it in HBase with minimal configuration.
12.11.1.1. Install the GeoMesa NARs¶
Follow the steps under Installation to install the GeoMesa processors in your NiFi instance. This tutorial requires the GeoMesa Kafka and HBase NARs, as well as the standard GeoMesa service NARs.
12.11.1.2. Add and Configure the Processors¶
The first step is to add two processors to your flow, a GetGeoMesaKafkaRecord processor and an
AvroToPutGeoMesaHBase processor. Connect the output of the Get processor to the input of the Put
processor:
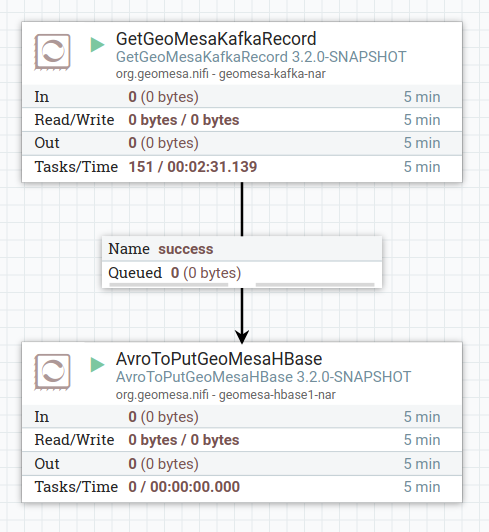
For a robust system, you would want to add further processing for handling successes and failures. For this example, just auto-terminate all other connections for simplicity.
Next, create a new controller service by clicking ‘Configure’ on the NiFi flow, then going to the Controller
Services tab and clicking the + button, then selecting the GeoAvroRecordSetWriterFactory. The
GeoAvroRecordSetWriterFactory can be left with its default configuration, which is to use NiFi expressions.
The GetGeoMesaKafkaRecord processor will populate the necessary attributes according to the feature type
being read:
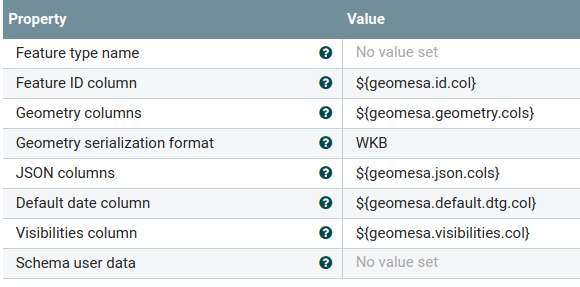
The GetGeoMesaKafkaRecord processor will pull data off of the GeoMesa Kafka topic and write it out using
a NiFi record writer. The processor can output data in any format supported by the NiFi records API, but for
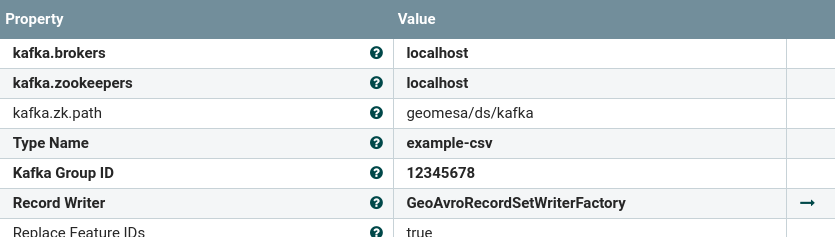
this example we’re going to use GeoAvro to simplify the ingest into HBase. Configure the processor by
setting the appropriate Kafka connection parameters and setting the GeoAvroRecordWriterFactory you just
created for the output. Set a unique Kafka group ID, to ensure that the processor reads all the data coming
from the topic:
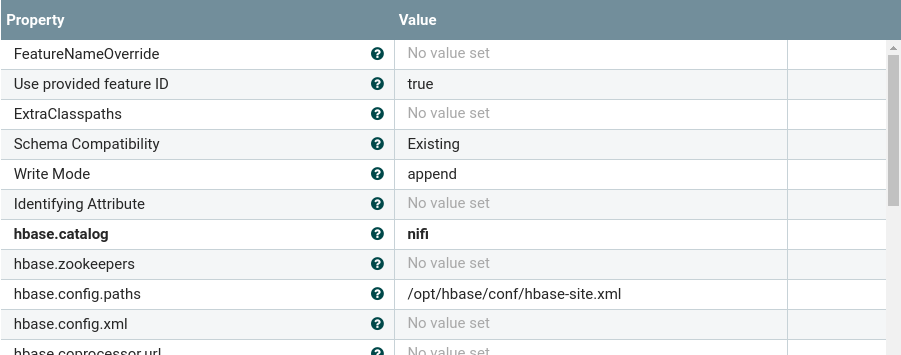
The AvroToPutGeoMesaHBase processor will read most the necessary configuration from the GeoAvro file, but
you still need to configure it with the hbase-site.xml file for your cluster, which will let it connect to HBase,
and a catalog table, which is where it will write out data:
Once all the processors and controller services are configured, enable them in the NiFi UI. If everything goes correctly, you’ll start seeing your Kafka data show up in HBase.