22.1. Architecture¶
GeoMesa Spark provides capabilities to run geospatial analysis jobs on the distributed, large-scale data processing engine Apache Spark. This provides interfaces for Spark to ingest and analyze geospatial data stored in GeoMesa Accumulo and other data stores.
GeoMesa Spark is divided into two modules.
GeoMesa Spark Core (geomesa-spark-core) is an extension for Spark that takes
GeoTools Query objects as input and produces resilient distributed datasets
(RDDs) containing serialized versions of geometry objects. Multiple
backends that target different types of feature stores are available,
including ones for GeoMesa Accumulo, other GeoTools DataStores, or files
readable by the GeoMesa Convert library.
GeoMesa SparkSQL (geomesa-spark-sql), in turn, stacks on GeoMesa Spark
Core to convert between RDDs and DataFrames. GeoMesa SparkSQL pushes down
filtering logic from SQL queries and converts them into GeoTools Query objects,
which are then passed to the GeoMesaSpark object provided by GeoMesa Spark Core.
GeoMesa SparkSQL also provides a number of user-defined types and functions for
working with geometry objects.
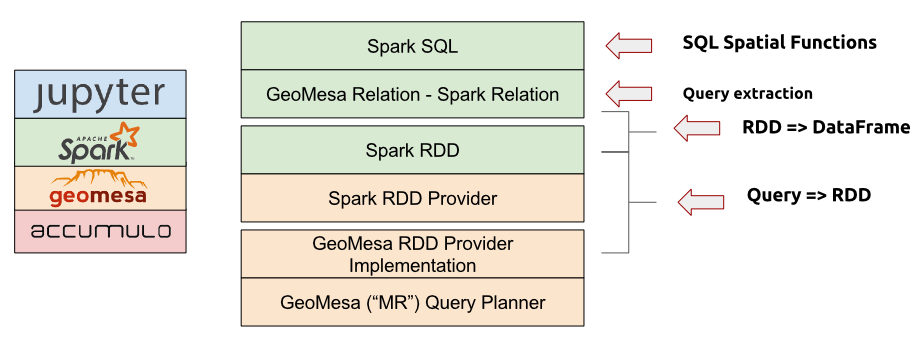
A stack composed of a distributed data store such as Accumulo, GeoMesa, the GeoMesa Spark libraries, Spark, and the Jupyter interactive notebook application (see above) provides a complete large-scale geospatial data analysis platform.
See GeoMesa Spark: Basic Analysis for a tutorial on analyzing data with GeoMesa Spark.